

My passion lies in Artificial Intelligent, and I want my legacy to be in the field of Health Care, using AI. So in hopes to make my dream come true as well as to practice OOP approach of implementing neural networks I will start the first part of long series of Denosing Lung CT Scans. I am going to start this series off with implementing the vanilla Auto Encoder, with Adam Optimizer.
NOTE: All of the DICOM images are from Cancer Image Archive Net, if you are planning to use the data please check with their Data Use-age policy. Specifically I will use DICOM images from Phantom FDA Data Set.
Training Data and Generated Noise Data




The idea is very simple, we have original DICOM image as seen left, and we are going to add some random noise to make the image look like right.

We can achieve this by adding random Gaussian distribution noise and multiplying it by some constant value.
Network Architecture (Graphic Form)

Black Box → Input DICOM image of 512*512 dimension
Blue / Green Square → Encoder Portion, 3 convolution operation and in the final layer we vectorize the image (Flatten)
Red / Yellow Square → Decoder Portion, takes input the encoded vector, and reshapes it to perform 3 layers of convolution operation.
As seen above, the components that make up the Auto Encoder are very simple and plain.
Network Architecture (Object Oriented Form)

As seen above, each of the model have three different functions.
a. Initialize → Initialize all of the weights in the model
b. Feed Forward → Depending whether the model is an Encoder or a Decoder, it either takes image as an input or encoded vector as input, and performs standard feed forward operation.
c. Back Propagation → This is the KEY function of the model, where we calculate the error rate for each layer and adjust the model’s weight to learn optimal weights.
Feed Forward Operation (Encoder / Decoder)

Red Box → Convolution Operation Portion for Encoder
Blue Box → Fully Connected Layer Operation Portion for Encoder

Blue Box → Fully Connected Layer Operation for Decoder
Red Box → Convolution Operation for Decoder
Two things I wish to note.
1. The order of operation is reversed from Encoder to Decoder . (Or in other words mirrored.)
2. To perform Dimensionality reduction, we are going to use Mean Pooling in the Encoder. And to up-sample image we are simply going to repeat each element in the Matrix in the Decoder.
Back Propagation (Encoder / Decoder)

Red Box → Adam Optimizer Update for Encoder
Blue Box → Performing Back Propagation for Encoder
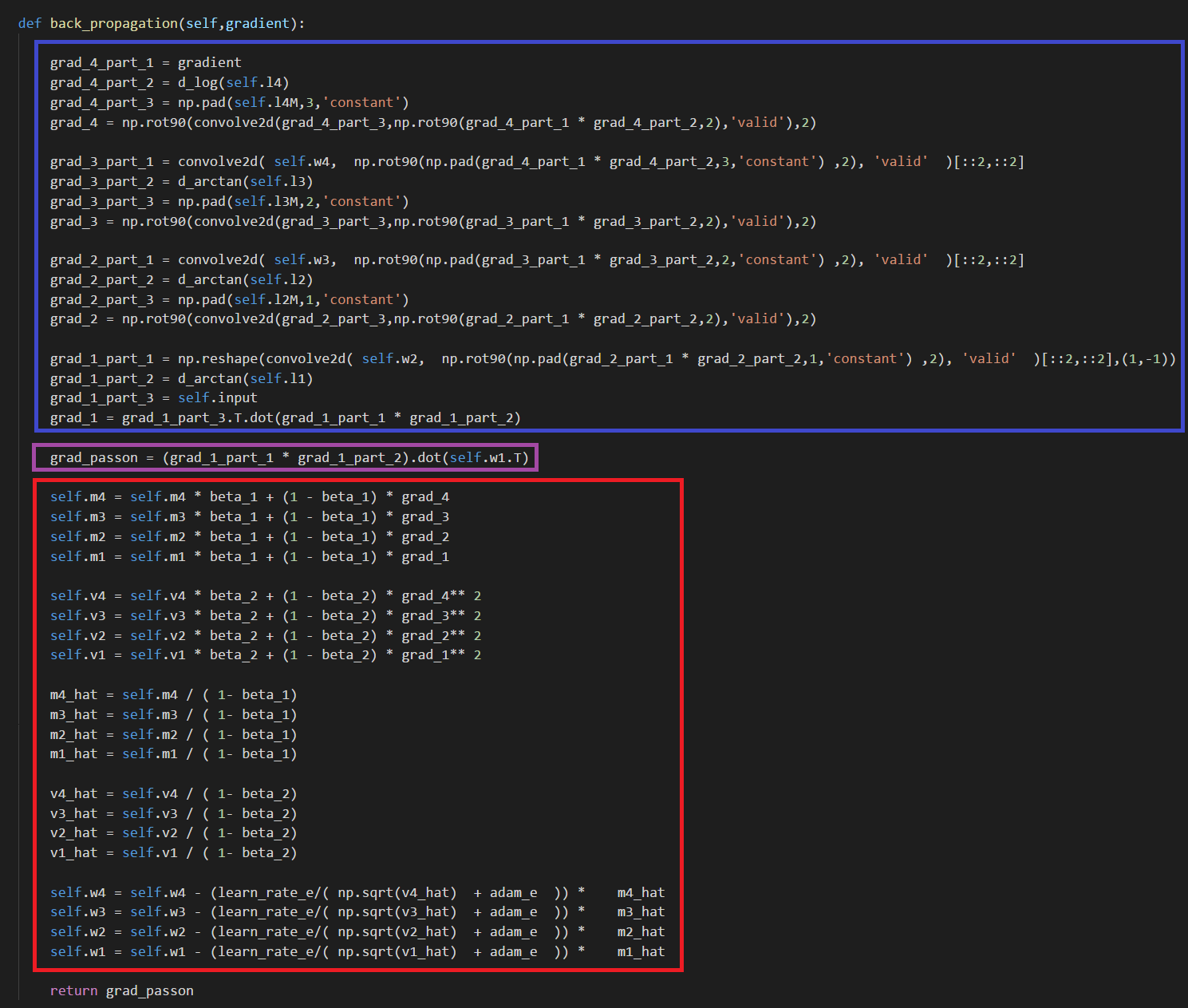
Blue Box → Performing Back Propagation for Decoder
Purple Box → To pass on the gradient to the Encoder, calculate the gradient to pass on before updating the weights
Red Box → Adam Optimizer Update for Decoder.
Naive Cost Function

For this vanilla Auto Encoders, I am going to use naive cost function which is L2 Squared cost function, but with 1/4 at the denominator rather than 1/2. I realize that there are many other cost function we can use here such as SSIM, or we can even use VGG 16 as a cost function as shown in the paper “The Unreasonable Effectiveness of Deep Features as a Perceptual Metric”. But for now lets stick to L2.
Training and Results — Vanilla Stochastic Gradient Descent

I was actually amazed with the result. I thought the decode image would be pitch black or all gray scale image, however I was really surprised that by the fact that few black spots can be seen in the middle of the decoded image.
Training and Results — Adam Optimizer (High Learning Rate)
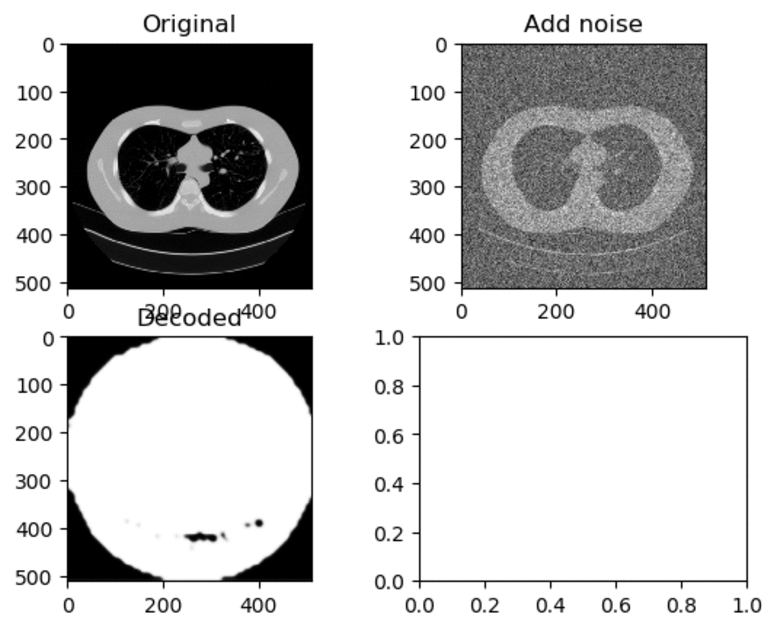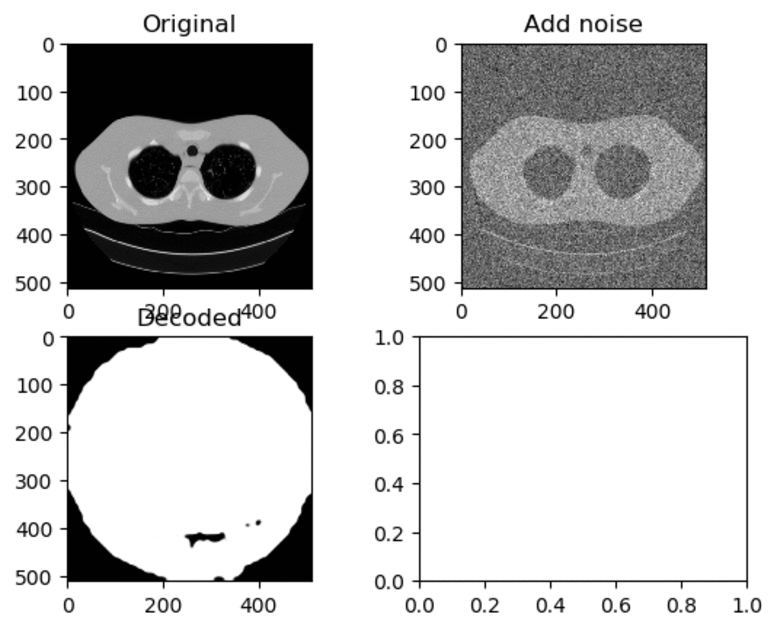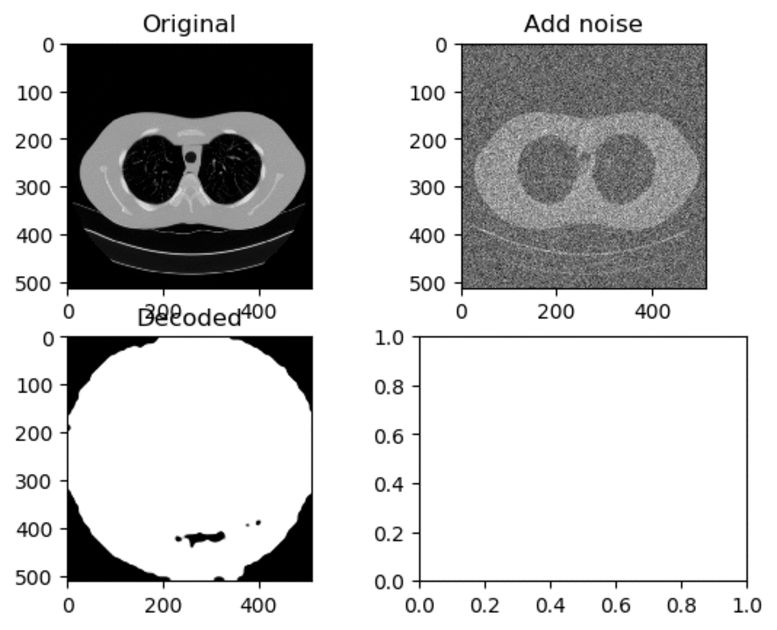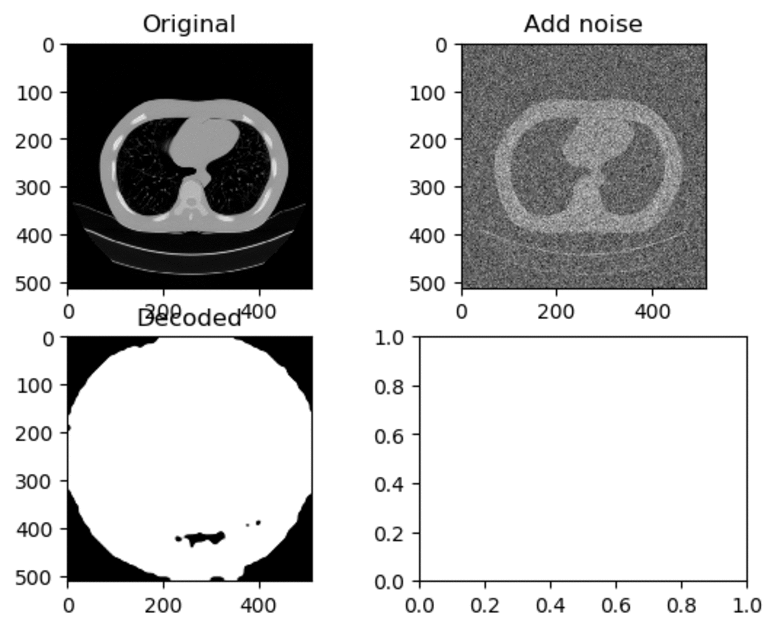
Learning Rate for Encoder → 0.0005
Learning Rate for Decoder → 0.001
As seen above, when the learning rate have been set to a high value, the decoded image just look like a white circle with black random noise.
Training and Results — ReLU Activation Function (High Learning Rate)

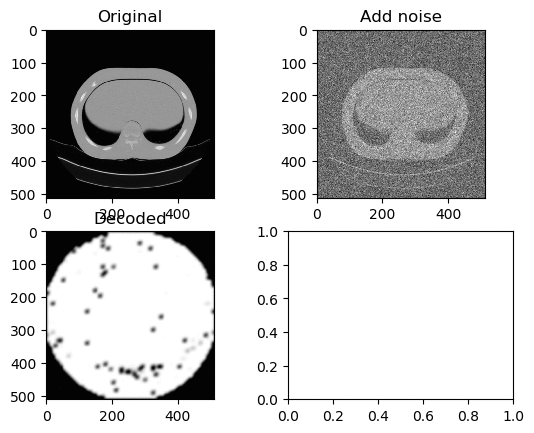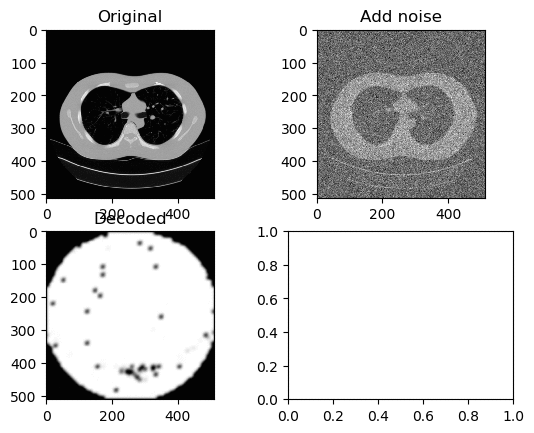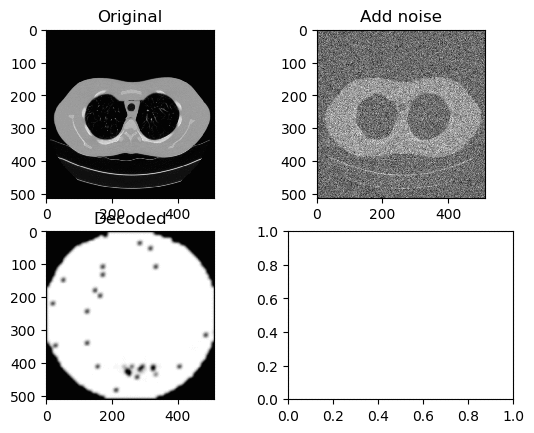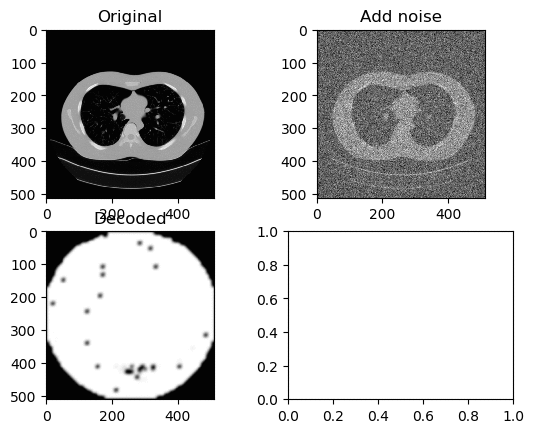
Learning Rate for Encoder → 0.000006
Learning Rate for Decoder → 0.0000006
Left GIF is the first 50 epoch, and the right GIF is the final 50 epoch, so 100 epoch in total. And again we can see the same trend of ‘white circle’ forming in the center of the decoded image.
Training and Results — ReLu Activation Function (Low Learning Rate)
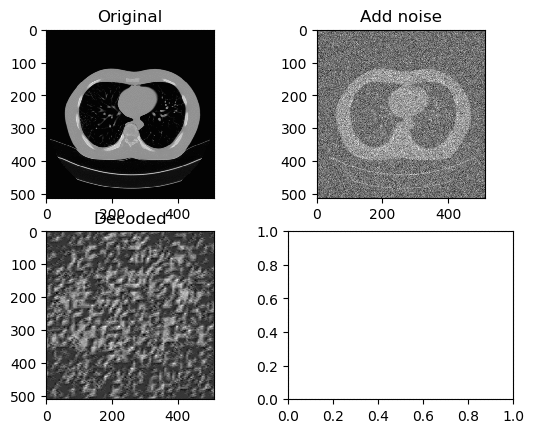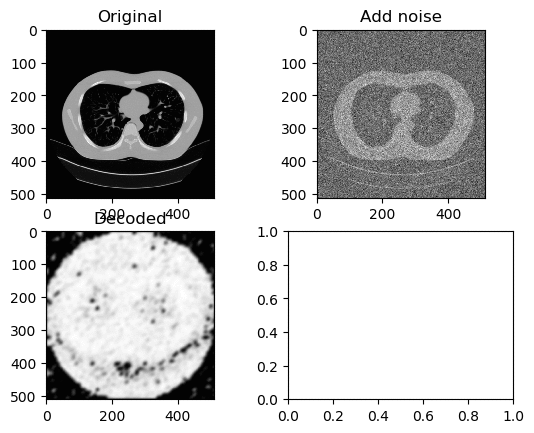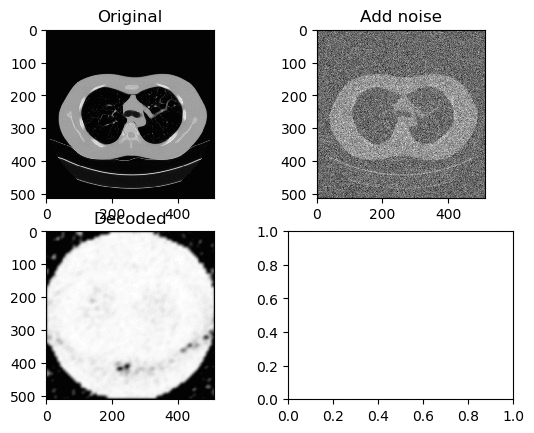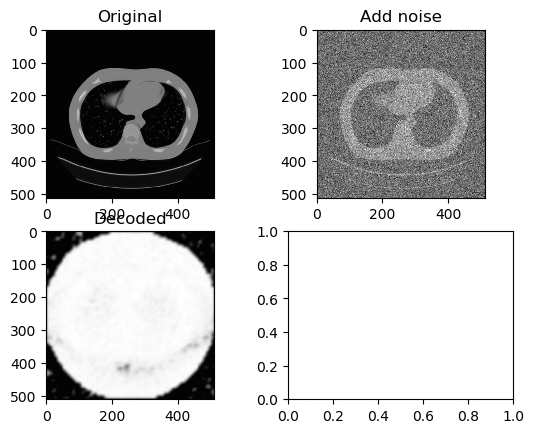
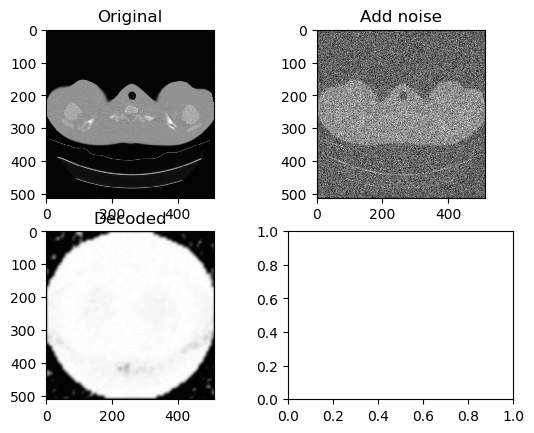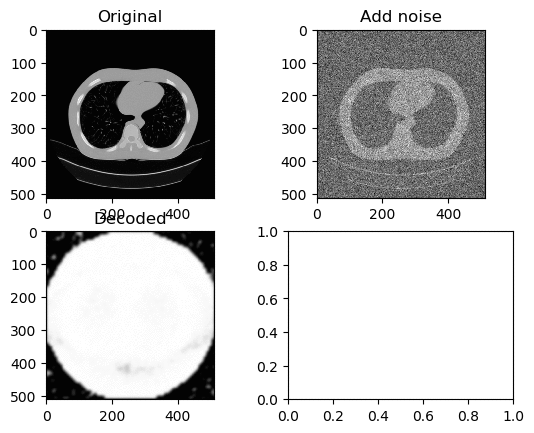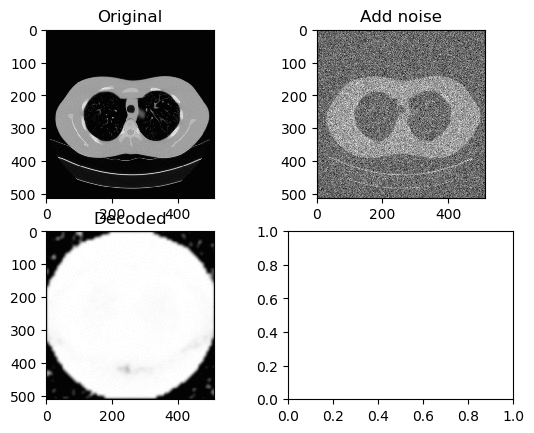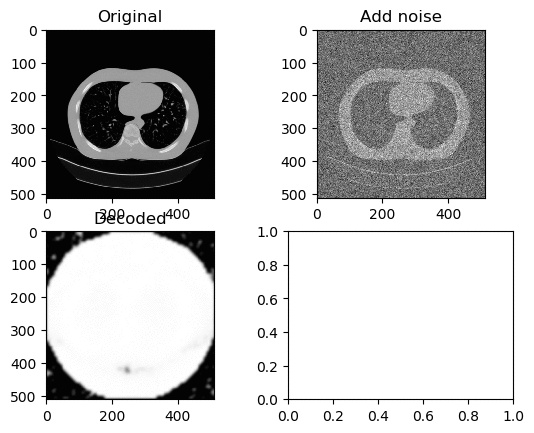
Learning Rate for Encoder → 0.0000001
Learning Rate for Decoder → 0.00000001
Left GIF is the first 50 epoch, and the right GIF is the final 50 epoch, so 100 epoch in total. At a low learning rate we can kinda see the lung portion of the image (Left GIF), however as learning goes on, again the white circle appears.
Training and Results — Tanh/Arctanh Activation Function (High LR)
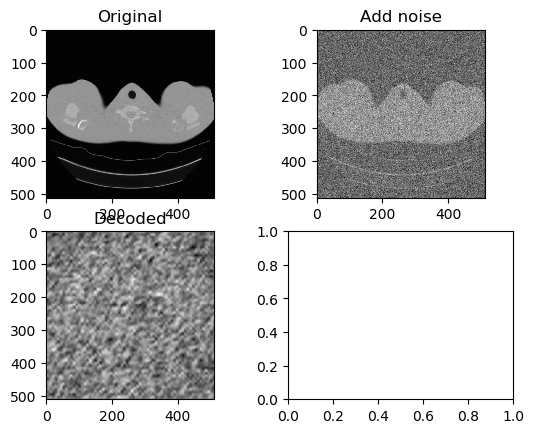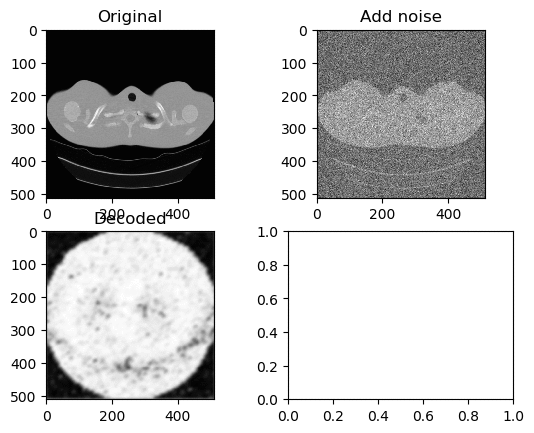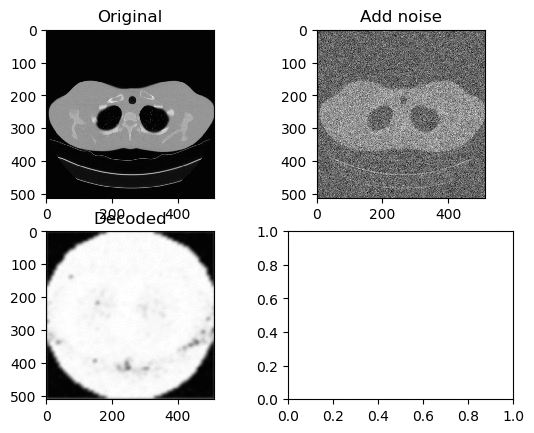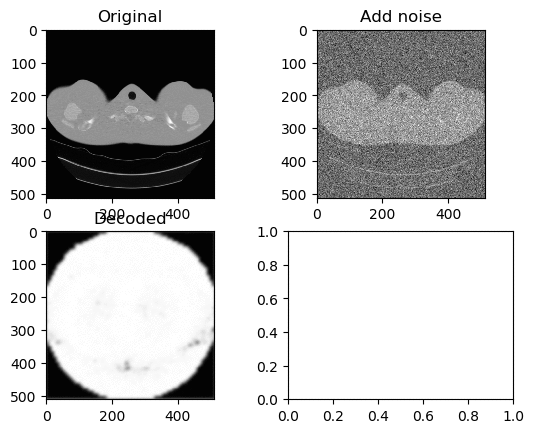

Learning Rate for Encoder → 0.000006
Learning Rate for Decoder → 0.0000006
Left GIF is the first 50 epoch, and the right GIF is the final 50 epoch, so 100 epoch in total. Very similar with ReLU activation model with High Learning Rate, but again ends with the white circle.
Training and Results — Tanh/Arctanh Activation Function (Low LR)

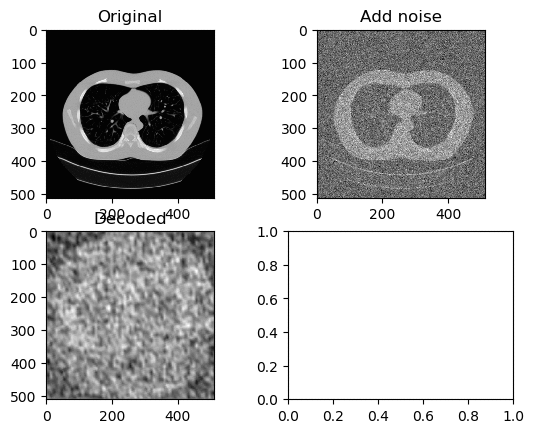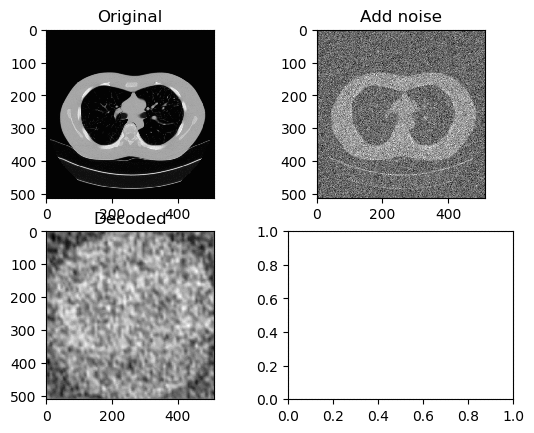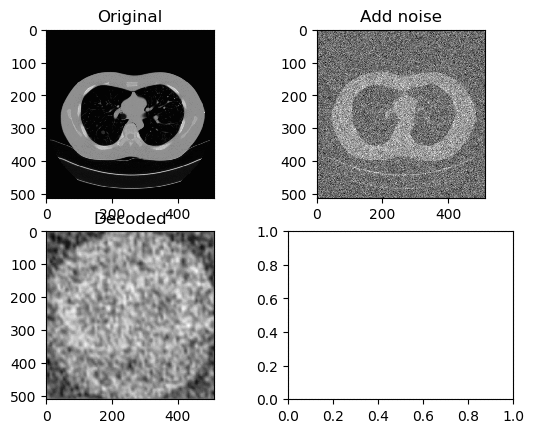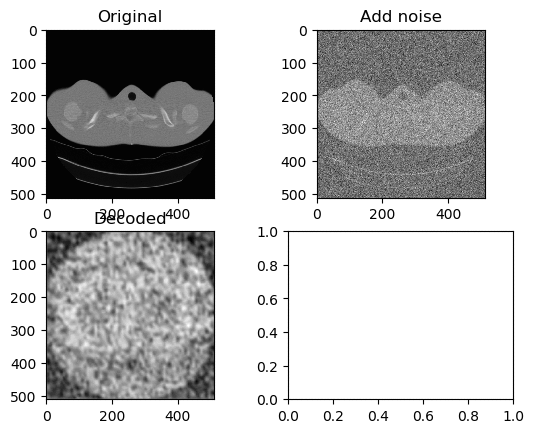
Learning Rate for Encoder → 0.0000007
Learning Rate for Decoder → 0.0000001
Left GIF is the first 50 epoch, and the right GIF is the final 50 epoch, so 100 epoch in total. So tuning the learning rate to be low was a simple solution, however it is nowhere near we can say that the image have been successfully denoised.
Cost over Time


Whether I choose to use ReLU, Tanh, or Arctan activation function, the cost seem to decrease over time, however if you take a look at the Y axis, it is no where near 0 and not in a range that produces an acceptable denoised images.
Interactive Code

I moved to Google Colab for Interactive codes! So you would need a google account to view the codes, also you can’t run read only scripts in Google Colab so make a copy on your play ground. Finally, I will never ask for permission to access your files on Google Drive, just FYI. Happy Coding!
Now running this code is bit complicated since I used my own data set. However don’t worry I uploaded all of the DICOMs that I used to my public Gitlab, to access it please follow this link. To access the main page of the repository please click here. Now please follow the step by step tutorial.

- Download the ‘lung_data_small.zip’ file from the link above.

2. Copy the Code in Google Colab, into your own play ground. Upon running the code, a small button will pop up as seen above. (Green Box). Click Choose Files and choose the recently Downloaded ‘lung_data_small.zip’ file.
3. The program will finish uploading the data into Google Colab and it will continue running.
So with the above short tutorial in mind, please click here to access the interactive code.
Final Words
I am sorry to say this, to my own model. But I didn’t expect much from this vanilla model. However I believe Auto Encoders are fascinating algorithms and I think there are HUGE potentials with Auto Encoders.
If any errors are found, please email me at jae.duk.seo@gmail.com.
Meanwhile follow me on my twitter here, and visit my website, or my Youtube channel for more content. I also did comparison of Decoupled Neural Network here if you are interested.
Reference
- A growing archive of medical images of cancer. (n.d.). Retrieved February 12, 2018, from http://www.cancerimagingarchive.net/
- Gavrielides, Marios A, Kinnard, Lisa M, Myers, Kyle J, Peregoy, Jenifer, Pritchard, William F, Zeng, Rongping, … Petrick, Nicholas. (2015). Data From Phantom_FDA. The Cancer Imaging Archive. http://doi.org/10.7937/K9/TCIA.2015.ORBJKMUX
- Cancer Imaging Archive Wiki. (n.d.). Retrieved February 12, 2018, from https://wiki.cancerimagingarchive.net/display/Public/Phantom FDA#9d6953e17646457293a77021aa4cdb37
- DICOM in Python: Importing medical image data into NumPy with PyDICOM and VTK. (2014, October 25). Retrieved February 12, 2018, from https://pyscience.wordpress.com/2014/09/08/dicom-in-python-importing-medical-image-data-into-numpy-with-pydicom-and-vtk/
- 1. (2017, August 04). Autoencoders — Bits and Bytes of Deep Learning — Towards Data Science. Retrieved February 12, 2018, from https://towardsdatascience.com/autoencoders-bits-and-bytes-of-deep-learning-eaba376f23ad
- How to make two plots side-by-side using Python. (n.d.). Retrieved February 12, 2018, from https://stackoverflow.com/questions/42818361/how-to-make-two-plots-side-by-side-using-python
- What is the opposite of numpy.repeat? (n.d.). Retrieved February 12, 2018, from https://stackoverflow.com/questions/40617710/what-is-the-opposite-of-numpy-repeat
- J. (2017, February 27). JaeDukSeo/Python_Basic_Image_Processing. Retrieved February 12, 2018, from https://github.com/JaeDukSeo/Python_Basic_Image_Processing
- Ruder, S. (2018, February 10). An overview of gradient descent optimization algorithms. Retrieved February 12, 2018, from http://ruder.io/optimizing-gradient-descent/index.html#adam
- 1. (2017, July 26). AutoEncoders are Essential in Deep Neural Nets — Towards Data Science. Retrieved February 12, 2018, from https://towardsdatascience.com/autoencoders-are-essential-in-deep-neural-nets-f0365b2d1d7c
- Zhang, R., Isola, P., Efros, A. A., Shechtman, E., & Wang, O. (2018). The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. arXiv preprint arXiv:1801.03924.
