

Most artificial intelligence(AI) systems nowadays are based on a single agent tackling a task or, in the case of adversarial models, a couple of agents that compete against each other to improve the overall behavior of a system. However, many cognition problems in the real world are the result of knowledge built by large groups of people. Take for example a self-driving car scenario, the decisions of any agent are the result of the behavior of many other agents in the scenario. Many scenarios in financial markets or economics are also the result of coordinated actions between large groups of entities. How can we mimic that behavior in artificial intelligence(AI) agents?
Multi-Agent Reinforcement Learning(MARL) is the deep learning discipline that focuses on models that include multiple agents that learn by dynamically interacting with their environment. While in single-agent reinforcement learning scenarios the state of the environment changes solely as a result of the actions of an agent, in MARL scenarios the environment is subjected to the actions of all agents. From that perspective, is we think of a MARL environment as a tuple {X1-A1,X2-A2….Xn-An} where Xm is any given agent and Am is any given action, then the new state of the environment is the result of the set of joined actions defined by A1xA2x….An. In other words, the complexity of MARL scenarios increases with the number of agents in the environment.
Another added complexity of MARL scenarios is related to the behavior of the agents. In many scenarios, agents in a MARL model can acts cooperatively, competitively or exhibit neutral behaviors. To handle those complexities, MARL techniques borrow some ideas from game theory which can be very helpful when comes to model environments with multiple participants. Specifically, most of MARL scenarios can be represented using one of the following game models:

· Static Games: A static game is one in which all players make decisions (or select a strategy) simultaneously, without knowledge of the strategies that are being chosen by other players. Even though the decisions may be made at different points in time, the game is simultaneous because each player has no information about the decisions of others; thus, it is as if the decisions are made simultaneously.
· Stage Games: A Stage Game is a game that arises in certain stage of a static game. In other words, the rules of the games depend on the specific stage. The prisoner’s dilemma is a classic example of stage game
· Repeated Games: When players interact by playing a similar stage game (such as the prisoner’s dilemma) numerous times, the game is called a repeated game. Unlike a game played once, a repeated game allows for a strategy to be contingent on past moves, thus allowing for reputation effects and retribution.
Most MARL scenarios can be modeled as static, stage or repeated games. New fields in game theory such as mean-field games are becoming extremely valuable in MARL scenarios (more about that in a future post).
MARL Algorithms and Game Theory
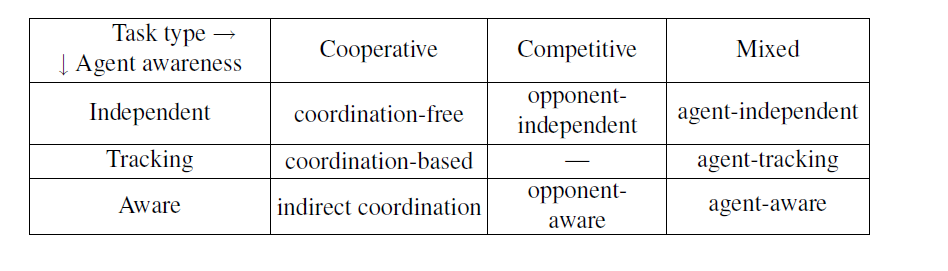
Recently, we have seen an explosion in the number of MARL algorithms produced in research labs. Keeping up with all that research is really hard but here we can also used a some game theory ideas. One of the best taxonomies I’ve seen to understand the MARL space, is by classifying the behavior of agents as fully-cooperative, fully-competitive or mixed. Below is a quick breakdown of the MARL space using that classification criteria.

To that level, we can add another interesting classification criteria is based on the type of task the agents in a MARL system need to perform. For instance, in some MARL environments, agents make decisions in complete isolation of other agents while, in other cases, they coordinate with cooperators or competitors.
Challenges of MARL Agents
MARL models offer tangible benefits to deep learning tasks given that they are the closet representations of many cognitive activities in the real world. However, there are plenty of challenges to consider when implementing this type of models. Without trying to provide an exhaustive list, there are three challenges that should be top of mind of any data scientists when considering implementing MARL models:
1. The Curse of Dimensionality: The famous challenge of deep learning systems is particularly relevant in MARL models. Many MARL strategies that work on certain game-environments terribly fail as the number of agents/players increase.
2. Training: Coordinating training across a large number of agents is another nightmare in MARL scenarios. Typically, MARL models use some training policy coordination mechanisms to minimize the impact of the training tasks.
3. Ambiguity: MARL models are very vulnerable to agent ambiguity scenarios. Imagine a multi-player game in which two agents occupied the exact same position in the environment. To handle those challenges, the policy of each agents needs to take into account the actions taken by other agents.
MARL models are called to become of the most relevant deep learning disciplines in the next decade. As these models tackle more complex scenarios, we are likely to see more ideas from game theory become foundational to MARL scenarios.
