
From: https://wordpress.com/block-editor/post/scieencerepository.data.blog

Philosopher’s Football is a board game invented by the late and legendary mathematician John Conway (another victim of the virus). In his honor, I built a website where you can play and learn more about the game at philosophers.football.
You can find someone else to play with online or locally and you can play against an AI player to get a feel for the game. The AI is still training as of this writing though — it may take a few weeks to get any good.
My goal today is to explain the game quickly and cover just enough reinforcement learning basics to explain the custom modification of the TD(λ) algorithm I am using, which I call Alternating TD(λ).¹ By the way, the TD means “Temporal Difference (learning)” and the λ is a hyperparameter setting the decay for the “eligibility trace” (similar to momentum). These will be explained below.
The implementation is from scratch in PyTorch and you can find the code on Github. I opted against using reinforcement-learning frameworks like OpenAI Gym because the algorithm is relatively simple. For a custom “environment” (i.e. the game) and modified algorithm, the frameworks add more complications than they solve.
For background, I’m assuming you’re familiar with PyTorch and some basics of Neural Networks, specifically what they are and backpropagation used in Stochastic Gradient Descent (SGD) (with momentum). The current implementation uses a Residual (Convolutional) Neural Network, essentially a smaller version of ResNet, but that isn’t important to understanding this article. No prior knowledge of reinforcement learning is assumed.
The rest of this article briefly covers the game then gets into basics of Reinforcement Learning. From there it covers the basics of Temporal Difference Learning and eligibility traces. Finally, it covers the modification I used for a symmetric 2-player board game, which I call Alternating TD(λ).¹
Philosopher’s Football
I built a website at philosophers.football for the game so you can experience it yourself. Words can’t do everything justice. To get a feel for it, you can read the rules and then play in sandbox mode (against yourself) or against a baseline bot like RandoTron, who always plays randomly.
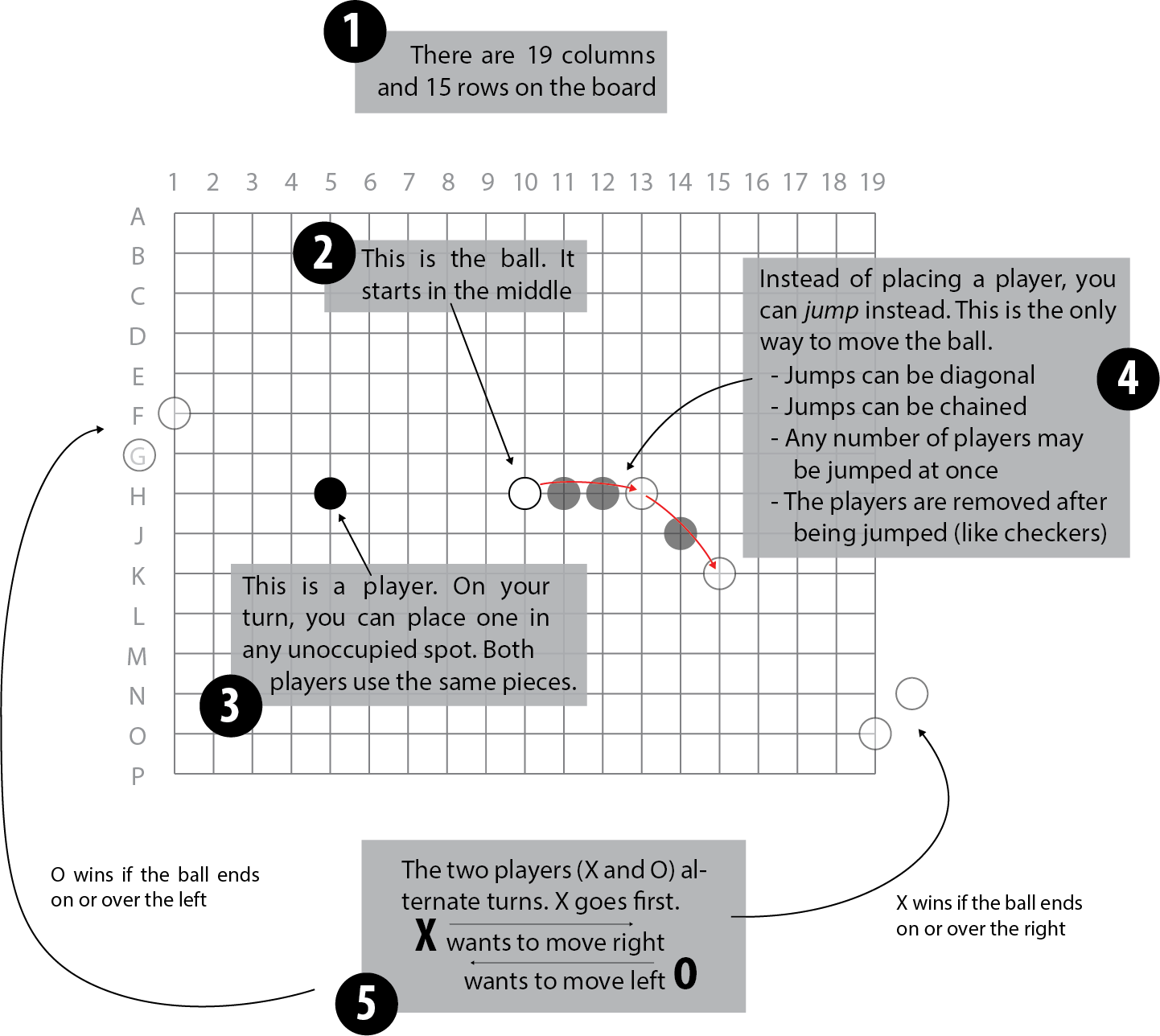
Otherwise, here is a condensed version of the rules, shorn of some of the details. On a 19×15 board like a Go board (often used for the game), stones are placed. There is only ever a single white stone, the ball. The black stones are “players”. The two opponents are called X and O by tradition. Both X and O can either place a player or jump the ball over some players on their move. X wins if the ball ends up on or over the right-most column; O wins on the left.
The game was played at Cambridge by John Conway and described in a book, Winning Ways for your Mathematical Plays. It is named after a hilarious Monty Python skit. Conway may be most famous for his Game of Life and work on the classification of the finite simple groups, but he did a number of other interesting things in his lifetime!
I chose to work on this game when I read about Conway’s viral demise and before thinking about the reinforcement learning problems. But the game later turned out to have a very useful symmetry property that will substantially simplify the reinforcement learning discussed below.
Consider the case where you are playing as X and it is your move. You will want to consider O’s response to your move. After your move, it is O’s turn. Now, if we turn the board around, it again appears to be your turn and you are playing towards the right (as X). Because the two players use exactly the same pieces, understanding how to evaluate the position you face as X is exactly the same as understanding the position you face as O.
This is slightly different than games like Tic-Tac-Toe, Chess, or Go, in which, for example, you may want to use your evaluation of a position after you move to inform how much you like a position before you move (or vice versa). There are other ways to solve this issue, but Philosopher’s Football has this nice symmetry which eliminates it.
Reinforcement Learning Basics
My goal in this section is not to write a complete introduction to reinforcement learning. Instead, my goal is to make this “as simple as possible but no simpler” for our limited purposes of explaining the (Alternating) TD(λ) algorithm.² In particular (for those in the know), a 2 player win/loss game doesn’t need rewards (R) or a discount-rate (γ), so I will pretend these don’t exist. The game is not stochastic, so only the deterministic case will be treated. We also won’t talk about Q-learning or policy-gradients.
The State (S)
Here is the setup. There are states S. For us, each is a board position assuming X is to move. We can assume it is X to move by the symmetry discussed above. Counting only states where the game is not over, there are substantially more possible states (#S ≈ 10⁸⁸) than atoms in the universe. Of course, most states are unlikely to occur in actual gameplay.³
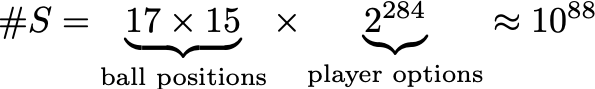
There are also two “terminal” states where the game is over. One for the case where X has won and one for O. All positions resulting in one of the two are (respectively) the same.
Time (t)
Now a game consists of a series of states at various times. Denote the time as t with t=0 the beginning of the game, t=1 after the first move is made, and so on. Furthermore, let t=∞ denote the end of the game (though it does not in fact take infinite time).
We will denote the state at various times with a subscript. For example Sₒ is the state at the beginning of the game. Likewise with subscripts 1, t, or ∞.
The Actions (A)
Given a state S, there is a set of possible actions (moves) that can be taken by the player whose turn it is (again, we will always consider X to play). Denote this set of actions A(S), since it depends on the state. An individual action will be denoted in lower case as a.
In context, an action is either a placement of a piece (maximum of 19⨉15–1=284 possible) or one of the available jumps (there could be a lot of possible jumps if you arrange the pieces properly). For a terminal state (the game is over), the set of actions will be treated as empty.
As before, we will use subscripts to denote the action set at a given time, or the action taken at a given time. For example, Aₒ = A(Sₒ) is the set of possible actions at the beginning (284 possible placements and no possible jumps). Likewise, aₒ is the action taken at time 0, namely the first move.
The Policy (π)
The policy π is the core of what it means to play a game. Given a state S, you have to choose an action to take!
Now, even in a deterministic, perfect information game like Philosopher’s Football, a policy could be stochastic (somewhat random). Consider the policy “what John Conway would play.” Namely, given a state S with X to move, what move would John Conway make? Whatever it is, play that.
Now, this Conway policy isn’t simple (good luck evaluating it on a computer). But it is certainly a policy.⁴ It is also not deterministic. (Most) people do not always make the same move given the same position. This would first of all be hard to remember and second be very boring.
So we will consider the policy to be a function π(a|S) giving the probability of taking action a given the state S. Note that we must have that the action a is a legal move (a∈ A(S)). Also, the policy function won’t be defined for the terminal (game-over) states.
Now making things, non-deterministic tends to make them more complicated without being much more enlightening. So through, feel free to consider the case where the policy function just takes as input a state and gives as output an action.
The Value Function
There is a value function v(S) taking as input a state S and returning the “value.” In our case, the value will be the probability of the player whose move it is winning. It is valued between 0 and 1.
We must also add the restriction that the value function evaluated at the two terminal (game-over) states is always 0 when O won and 1 when X won. (This is because we can assume we are always evaluating for X, by symmetry).

Now, the value function comes in a few flavors (at left). With perfect play in a deterministic perfect-information game, the game must certainly end with a win for X, a loss, or an infinite loop which we shall call a draw with value ½. For our purposes, we may assume the third never happens.
With a given policy π and assuming that the opponent is playing the same policy, there is an “ideal” function that determines exactly the probability of winning, a number between 0 and 1. If the policy is deterministic, the probability of winning is either 0 or 1 (ignoring the draw case).
Unfortunately, if we knew how to play perfectly, there would be no need to train a computer to play. Also, the ideal function is computationally intractable:
- If it were a simple table with input/output values, it would have to have one entry for each state, of which there are about 10⁸⁸ – more than there are atoms in the universe.
- There is no particular known mathematical function that would simplify the calculation (though perhaps you could try to find one).
- Finally, we could compute the ideal function exactly through simulation (playing games). But if π is stochastic this will take too long to get an exact answer.
- If π is deterministic, the ideal function will still not be useful, because it won’t tell us how to learn, that is, to make π better.
So instead, we will use the approximate value function, which we will henceforth just refer to as v. Most commonly, the approximate value function can be implemented with a neural network, which is what we shall do.
Learning
So far all we have done is set up a context and some notation. We haven’t described how our AI player is going to learn to play a better policy. There are (of course) a variety of algorithms to do this. Roughly speaking, a learning algorithm could try to learn a policy function π directly (policy-gradients). It could try to learn to decide which actions are best (Q-learning). Or it can just learn the value function – simply learning how good a position is. We are only going to discuss the last case.
In this context, given a value function v we can make our policy “choose the move that results in the resulting position that we think is best for us.” In particular, since our game is deterministic, choosing an action a is equivalent to choosing the next state S at time t+1. So, abusing notation slightly and treating π as a simple function from states to actions:

In the π(a|S) notation, π is 1 if a is the best move, and 0 otherwise.
Note that we have elided for now the issue of dealing with the fact that it is O to play after X, and we have said all states assume X is to play. For the time being, the value function is conceptually X’s estimate of their likelihood of winning given the state S including the information about who is to move.
Recap
Our AI player pursues some policy π which takes a state S at time t and determines an action (move) a – either giving a single move or probabilities of each move. There is also a value function v that estimates our probability of winning given a state and when following policy π. Conversely, if π is “pick the best move” (or a probability distribution over a few of the best ones), then we can treat v as a first-class object and derive π from it. Our learning problem is reduced to a good estimate v.
Here’s a recap of the symbols we defined and their brief interpretation.

Temporal Difference Learning: TD(0)
So we have set up the basic context of reinforcement learning. Our goal is to estimate a value function v. At every step, the AI player just chooses the move that results in the best resulting value (i.e. probability of winning). This is a deterministic strategy, but we can make it random (less boring) by giving a probability distribution over the top 3 or 5 moves or something.
Now how are we going to learn v? For the time being, let’s consider the case where v is simply a giant table with all the possible states and their values. Computationally impossible here but conceptually straightforward.
Here is a list of upgrades we can make to our learning algorithm, starting from the obvious and proceeding towards the clever.
- The simplest way to evaluate v(S) would be with a deterministic strategy. Given a state, just play out the game and see who wins.
- If the strategy isn’t deterministic, we could simulate a number of games, sampling a move from the probability distribution at each step. Overall we would produce a sample of possible games that we can use to estimate the probability of winning. These are called Monte-Carlo methods.
- We can take advantage of the fact that after a move a from state S resulting in a new state Sʹ, we already know the new value v(Sʹ). And to be consistent, if we are making the best move, we would like to have v(S) = v(Sʹ). This is called bootstrapping (see equations below). Not to be confused with the term from statistics or the web framework.
- In general we can mix and match options (2) and (3): we can simulate out to 3 steps and then bootstrap, or do a linear combination of the two.
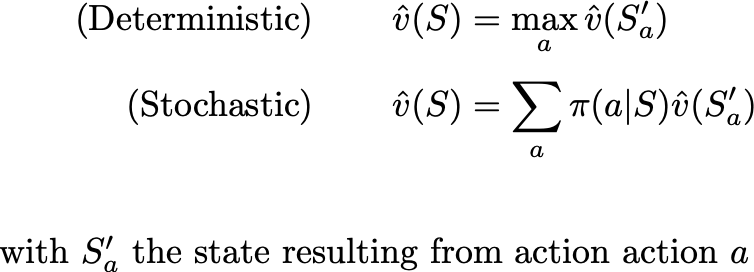
Option 3, temporal difference learning aka TD(0), is where the learning really come into play. We go through a series of states and at each step we update our estimate of v(S) to match our estimate of v(Sʹ). Generally we start with a table initialized with either random numbers or zeros, and we update with a learning rate α. We introduce a temporal difference δ and make our updates as follows:

Notice the subscripts carefully. Our value function v now changes at each time step, so we have to keep track of which time step we are evaluating at.
Off-policy learning
All of this would be quite boring if our bot just kept playing the same moves over and over again. It needs to try different moves to see if they’re any good. This is called the exploration-exploitation tradeoff and gets covered a lot, so I won’t talk about it much.
One of the benefits of our TD(0) algorithm is that, while we are playing the bot against itself and learning the approximate value function v, we can just make a random move and not make our update. This makes it very simple to try out new moves. Monte-Carlo methods run into issues because you have to simulate an entire game under the policy to learn about any of them. If you make a random (most likely bad) move in the middle, you have to try to figure out how that affects your estimates of earlier moves. This is possible, but comes with downsides (mostly high variance).
Using a Neural Network
Above we considered the case where the function v was just a table of values. To update v(S) we just change the value in the table. As discussed above, this tabular approach is computationally impossible for Philosopher’s Football. So we need to upgrade v to a neural network. It will take as input some representation of the state as a tensor or list of tensors. And it will produce as output a number between 0 and 1. We need to add a set of parameters (the network weights) w at each time t. So we clarify of our definition of v to now look like:

And we need to modify our update algorithms to use backpropogation:

Note a few things:
- We use gradient ascent. We want to make v(S) closer to v(Sʹ), not minimize its value (as in standard Stochastic Gradient Descent). The result of this update is that:

- The gradient ∇v is the (component-wise) derivative of v with respect to the parameters w at time t evaluated at the pre-existing w and S, as usual.
- No guarantees can be made about v evaluated at any other state after the update. The hope is that the neural network learns a representation of the state that allows it to generalize, just as in any other application.
Eligibility Traces: TD(λ)
Eligibility traces are essentially momentum as in Stochastic Gradient Descent, but in reinforcement learning they are motivated differently and have a different interpretation. They allow us to keep the simplicity of the TD(0) algorithm but gain the benefits of using Monte-Carlo methods.
Specifically, TD(0) suffers from the issue that we are learning the whole value function at the same time. So v(Sʹ) may not be a good estimate of v(S). In particular, after moving to Sʹ, the AI player moves to another state, call it Sʹʹ. If v(Sʹ) isn’t a good estimate of v(Sʹʹ), then it isn’t a good estimate to use for v(S) either. Monte-Carlo methods solve this by doing their updates after an entire game has been played, but in turn suffer when it comes to dealing with off-policy moves.
Eligibility traces are the solution. Similar to momentum in Stochastic Gradient Descent we add a trace z (initialized to 0) to our algorithm and with decay parameter λ < 1. We get the update at time t:

The trace matches the parameters w component for component. So if w is a vector, then z is a vector of the same length. Likewise substituting “tensor” for vector and “shape” for length. Likewise with “list of tensors” and “corresponding list of shapes.”
It’s worth considering what happens step-by-step. Let’s start at time t=0 and make the update. With the careful understanding that our derivatives are evaluated based on the current state
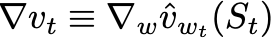
We get the following update at our first step (z is initialized to 0):
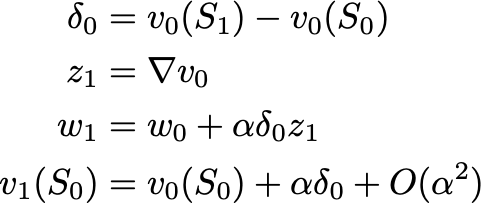
with v(S) updated to match v(Sʹ) just as before. The difference comes in at the next step:
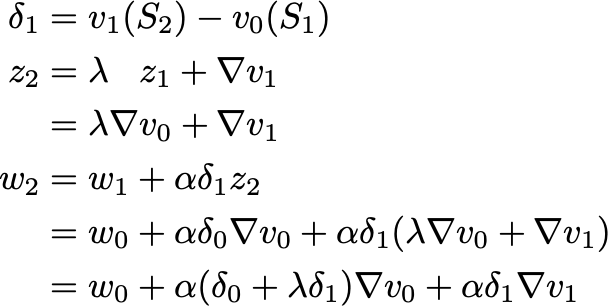
It’s as if we went back in time and made the update at time 0 account for the future, not-yet-known, difference between v(Sʹ) and v(Sʹʹ)! Suitably discounted by a factor of λ.
Note that the two derivatives were evaluated at different times with different parameters and inputs. This means we can’t write down any enlightening expression for the resulting v(Sₒ).
The final note for our algorithm is that, if we make an off policy action, we should just zero out the trace. The value of future positions is no longer informative for the moves we made in the past.
Recap
We’ve introduced more new notation. With a brief reprise of the standard stuff, we have the following summary:

Alternating TD(λ)
The whole point of this article is that a slight modification is needed to the TD(λ) to account for the fact that the game is a 2 player game. There are a variety of ways to deal with this, but the symmetry of Philosopher’s Football makes it very clean.
In particular, let’s interpret a state S as representing an arrangement of pieces with the underlying assumption that X is to play. Then v evaluates the probability of X winning. Use a † to indicate that the board has been turned around. Ignoring parameter updates for now, we have the following transformations when the AI player moves
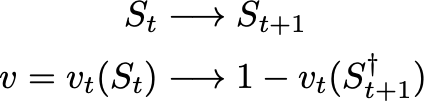
In particular, after playing, if we turn the board around (†) then the probability of winning has changed to 1-v. This will necessitate some changes in the algorithm.
Another change is necessary to take into the account that it’s desirable to compute derivatives at the same time as evaluation is done. Implicitly in the textbook TD(λ) algorithm, we first do a forward pass evaluation of states to choose a move and then compute the derivative with respect to the old state. This is obviously wasteful. Our complete algorithm for a step now becomes:

The tricky part is the minus sign in step 6! This is why I call it Alternating TD(λ). We make an update at time t based on the difference in values between times t+1 and t. If, at time t+2 we realize our t+1 value was an underestimate (so δ is negative), we need to increase our value-estimate for the state S at time t. Hence the alternating sign of the gradient to account for the alternating players.
Conclusion
Hopefully, you’ve learned a good bit about reinforcement learning as well as some of the extra complexity from a 2-player game. And if you haven’t yet, play the game at philosophers.football. The AI players are still training, but you can play against another human.
[1] I’m not sure if the algorithm is original. I based it off the textbook description in Sutton and Barto.
[2] paraphrase of Einstein.
[3] First of all because it is unlikely enough games will ever be played to achieve all of those states. Second, because any remotely competent player would have won long before those states were achieved.
[4] Technically to make this policy well defined, we should include all the information necessary to a human in the state variable: the time of day, whether they are hungry, whether Mercury is in retrograde, how many cats are in the room, whether their opponent is wearing a black hat, whether they believe the axiom of choice at the moment, etc. But this technicality won’t affect the main argument.
